Automatización de pruebas con Selenium

Una de las tareas más importantes dentro del proceso de desarrollo de software es la del testing, que nos asegura que la calidad del código producido sea la que el cliente espera por el precio que está pagando. Podemos mejorar la calidad mediante automatización de pruebas con Selenium, como veremos en breve.
El testing manual (pruebas manuales) es parte cotidiana de la industria del software, a medida que el programa va creciendo también aumenta la cantidad de tests (o pruebas) que se deben realizar regularmente sobre el producto. El testeo manual de todas las pruebas genera gastos cada vez más elevados por los recursos que se necesitan utilizar. La solución a este problema (al menos en cierta medida) es el uso de tests automatizados, que ejecutan las tareas de forma más rápida y desatendida.
Una de las herramientas más populares para hacer testing sobre aplicaciones web es Selenium.
¿Qué es Selenium?
Selenium es un conjunto de herramientas que nos permiten realizar pruebas sobre aplicaciones web. Selenium cuenta con varias partes como ser:
- WebDriver es la parte de Selenium que nos permite interactuar con las APIs de algún navegador en particular, profundizaremos un poco sobre este componente más abajo.
- IDE es una extensión disponible para Chrome o Firefox que básicamente nos permite grabar las acciones que realizamos sobre una página web para convertir dichas acciones en código.
- Grid es el componente que nos permite ejecutar nuestros tests de forma distribuida en máquinas (también llamados agentes) remotos distintos a la máquina que usamos. Estos agentes pueden tener distintas configuraciones e incluso distintos sistemas operativos.
Cuando codificamos nuestros tests E2E utilizamos métodos de Selenium que se relacionan con el driver (o controlador) del navegador sobre el que automatizaremos nuestros tests.
¿Qué es el WebDriver?
WebDriver es una especificación del W3C (World Wide Web Consortium) que establece una plataforma y un protocolo para poder comunicarse con un determinado navegador y controlar su comportamiento u obtener su estado. Esta especificación no está basada en un lenguaje de programación en particular.
Cada uno de los navegadores más populares cuenta con su implementación del WebDriver, chromedriver para Chrome y Chromium, geckodriver para FireFox, EdgeDriver para Edge entre otros.
Cuando se menciona el término Selenium WebDriver, se refiere al framework y al protocolo que se comunica con cualquiera de los controladores (o drivers) mencionados con anterioridad. Este framework ha sido implementado en varios lenguajes de programación, tales como Java, C# o Python. Los métodos del framework se encargan de comunicar al controlador qué acción deseamos realizar y éste se encarga de completarla en el navegador correspondiente.
Locators y Web Elements
Para la automatización de pruebas con Selenium necesitamos utilizar las funcionalidades que nos brinda el framework para esto podemos localizar un elemento en la página web (un input para colocar nombre de usuario, un botón, etc.) y ejecutar acciones propias al elemento que queremos localizar.
Para ubicar los elementos, Selenium cuenta con algunos métodos de localización que listamos a continuación:
- ID: para usar este localizador necesitamos conocer el atributo id del elemento web que queremos ubicar.
<input type="text" name="email" id="username" class="form-input"> - Name: para usar éste necesitamos el atributo name del elemento.
<input type="text" name="email" id="username" class="form-input"> - ClassName: este localizador requiere el atributo clase del elemento web, que generalmente se relaciona a un estilo CSS en particular.
<input type="text" name="email" id="username" class="form-input"> - TagName: con este localizador necesitamos el nombre de tag (etiqueta) del elemento web.
<input type="text" name="email" id="username" class="form-input"> - CSSSelector: con este localizador podemos usar selectores CSS estándar (aquí puedes ver algo más conciso).
- XPath: para hallar un elemento usando el estándar XPath de posicionamiento relativo o absoluto dentro de la página.
- LinkText: nos ayuda a encontrar un elemento en base al texto que tiene el enlace de dicho elemento.
<a href="https://cabrajeta.com">Este es un enlace de prueba</a> - PartialLinkText: igual que LinkText pero podemos buscar el elemento con solamente un fragmento del texto que contiene.
<a href="https://cabrajeta.com">Este es un enlace de prueba</a>
Los métodos de localización mencionados son usados dentro de Selenium para obtener objetos de localización, o locators. Estos locators nos ayudan a especificar un determinado elemento de la página web, de acuerdo a la siguiente sintaxis en C#:
private By locator => By.Id("username"); //Locator para obtener el elemento web
private IWebElement Username => Driver.FindElementBy(locator); //El Web Element en sí
public void SetUsername(string text) //Método para colocar texto en el Web Element
{
Username.SendKeys(text); //Método de Selenium para colocar Texto
}En el fragmento de código anterior se puede ver el uso del locator para obtener un web element y cómo realizar una acción predefinida en él usando Selenium.
Si bien aquí se ve código fuera de contexto, en el próximo post veremos todo lo que se necesita para hacer funcionar un código similar y automatizar una prueba con Selenium, paso a paso, incluyendo la adición de dependencias necesarias y los pre requisitos para tener nuestro entorno configurado para crear nuestros tests.
El patrón de diseño POM
El POM o Page Object Model es un patrón de diseño para testing web que es bastante popular por ser lógico, intuitivo, escalable y modular. El principio que se usa es el de tener una clase (objeto) por cada página que se tenga de la aplicación web (de ahí su nombre).
En cada clase tenemos los elementos web propios de dicha página como campos o propiedades y las acciones que soporta cada elemento (agregar texto, hacer click, seleccionar, deseleccionar, etc.) son agregadas como métodos del elemento, de forma atómica, es decir, cada método debe realizar solamente una acción sobre determinado elemento. De esta manera tenemos una separación entre la lógica de nuestro test y las posibles acciones que se pueden realizar sobre un elemento perteneciente a un determinado page object.
Podemos ir un paso más allá y crear clases helper que nos ayuden a realizar series de acciones secuenciales repetitivas que podamos extraer de la lógica para poder reusar estas series de acciones, llamándolas workflows.
Si aún separamos más las responsabilidades, podemos crear una nueva clase que solamente contenga las llamadas a los métodos de test y las aserciones (assertions) para poder verificar si el test pasó o falló durante la ejecución. De esta forma, el esquema de clases que tendríamos se vería algo como esto:
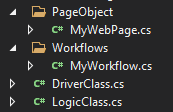
Donde:
- DriverClass es la clase donde tendremos la llamada a los tests y las aserciones.
- LogicClass es la clase donde estará la lógica del test.
- MyWorkflow es la clase donde pondremos las acciones secuenciales reusables.
- MyWebPage es la clase del page object, donde están los elementos web y las acciones para cada uno.
Con esta información ya podemos comenzar con lo básico de la automatización de pruebas con Selenium, en el siguiente post (como mencionaba) veremos cómo crear paso a paso un proyecto para comenzar a usar Selenium en nuestros tests E2E.